Turboboot - a major leap in decreasing cold boots
April 13, 2023
Welcome to Turboboot, the latest milestone in Banana's effort to decrease cold boots.
Turboboot is our new scaling and scheduler module. It is designed to be a fully decentralized scaler-scheduler module, meaning there is no longer a service needed to keep track of all models and GPUs. With Turboboot, you can see up to 90% improvement on your cold boot speeds.
We had a beta group of Banana customers running on Turboboot, here is what one customer has said about performance so far:

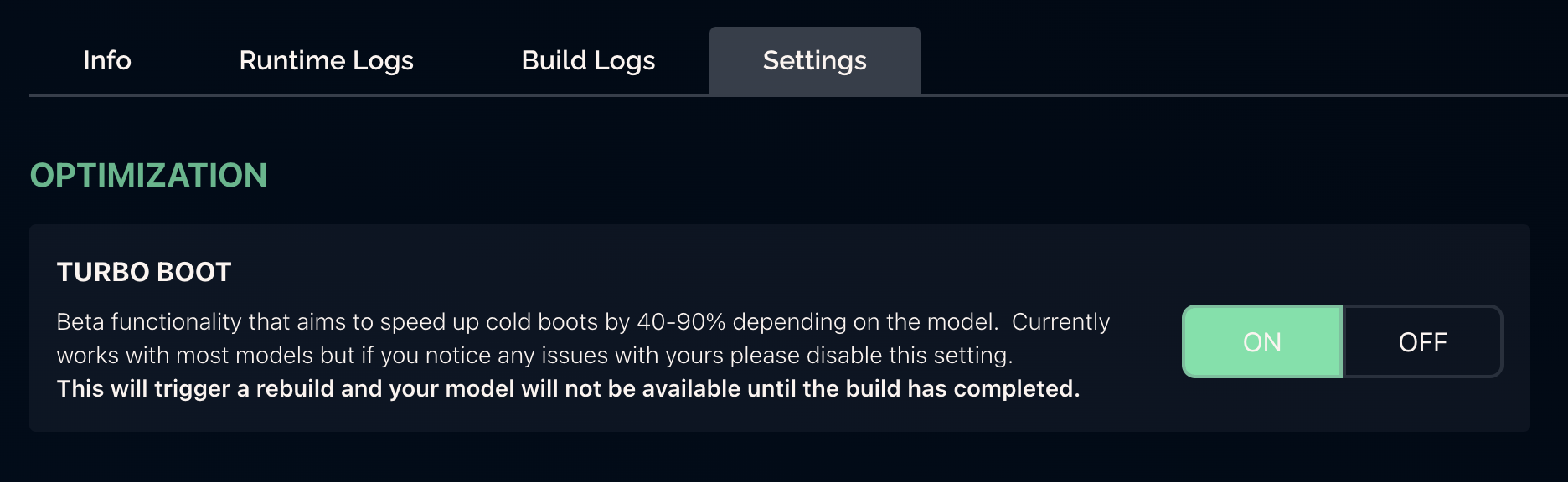
Turboboot is now available for all Banana users, you can enable it (on compatible models) in your Model Settings.
Turboboot Technical Synopsis
Turboboot was developed by the R&D team at Banana out of a core need to lower cold boot times for our customers.
Banana's infrastructure already had in-house optimizations that would speed up model load into memory, however, we noticed a large percentage of the cold boot time for customers was coming from the overhead within our autoscaling and scheduling services. We fixed this with Turboboot by merging our autoscaling and scheduling services into a single per-model service, which is decentralized, so essentially each model has its own scaler and scheduler instead of a global system.
Turboboot Performance Benchmarks
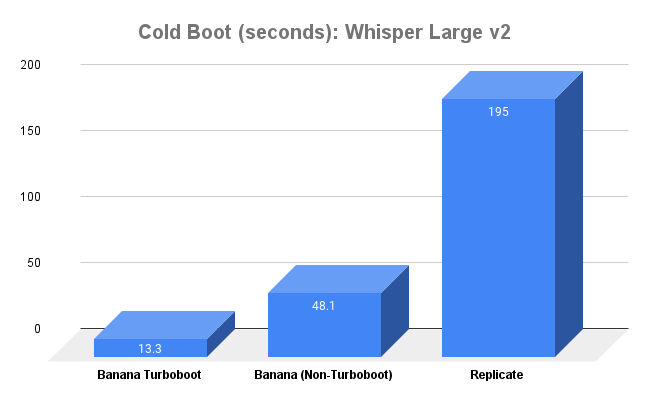
Turboboot has some of the fastest cold boot times in the industry. These benchmarks were run to compare cold boot and warm boot times between providers and models.
In this benchmark, we compare against our friends at Replicate, who provide excellent APIs. We’re all working on important problems; this benchmark is intended to show off improvements in Banana’s system, and not to diminish the great work being done by others in our community.
We are comparing Whisper Large v2, SAM (Segment Anything Model), Flan T5 XL, and Automatic1111 Stable Diffusion on Replicate, Banana (Non-Turboboot), and Banana Turboboot. We plan to benchmark on other platforms as well, let us know if you have a preferred platform you would like to see added.
Each benchmarked time is the average result of 10 calls ran for that model.

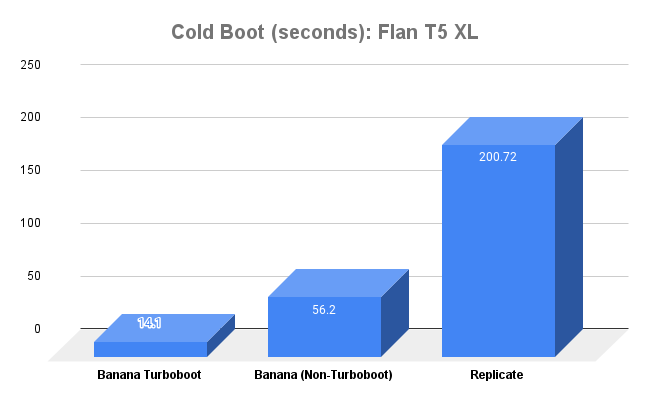
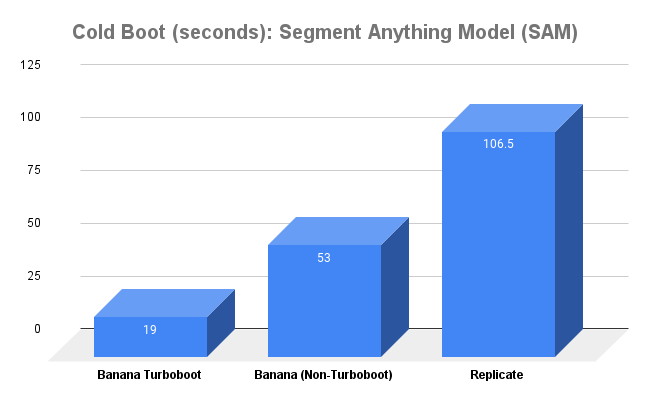
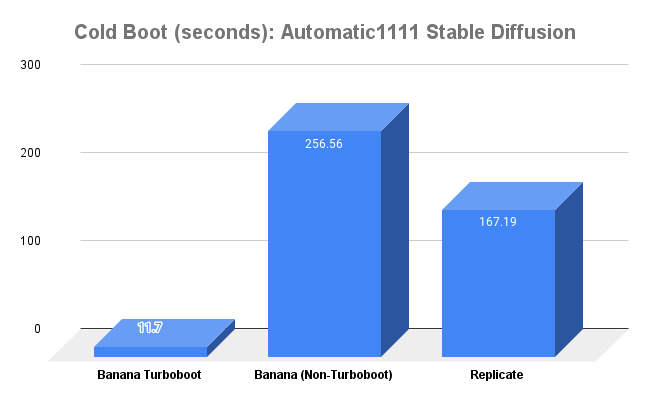

If you want to try these models on Turboboot for yourself, you can use one of our model templates to deploy in minutes.
Automatic1111 Stable Diffusion
R&D - Problem
Users on Banana were seeing slower cold boots than expected, which degraded UX for their customers which makes serverless GPUs a less feasible option for products where latency is important.
The actual load of the model onto the GPU was fast on Banana, as we have our in-house optimizations which speed this up significantly, however, there was a lot of overhead latency which was actually coming from our autoscaler and scheduler.
Autoscaler - Based on how many calls are coming to a model, this was used to scale up and down replicas accordingly.
Scheduler - When the autoscaler triggered a scale up, the scheduler would create a new model replica on a specific GPU that was free.
As Banana's customer base grew, the number of scale-up and down operations increased exponentially, slowing down the autoscaler because the autoscaler monitored and polled the request queue of each model. Eventually, our autoscaler went from scaling replicas in milliseconds to multiple seconds.
The scheduler, similar to the Kubernetes scheduler, was a centralized scheduler that maintained an inner state of active replicas and the GPUs available. As the number of scale-up events increased, the scheduler started to have race conditions where multiple replicas tried to be run on a single GPU, and as the number of GPUs increased in our cluster, the scheduler slowed down because the scheduling algorithm’s complexity was proportional to the number of GPUs in our cluster.
R&D - Solution
We fixed this with Turboboot, where we removed the autoscaler and scheduler completely. We replaced it with a single module that handles both scaling and scheduling together. The new Turboboot module is a decentralized service, meaning there’s no one service keeping track of all models and GPUs. We now have a module per each model, which tracks the requests for that model. When needed it scales up the model onto a GPU by directly querying the true GPU state, without keeping any cache of its own because each model has its own module. This increases the number of models deployed on Banana and doesn’t affect the latency of any single model.
Is your model Turboboot compatible?
Turboboot is compatible with all models that use the Potassium framework, and also with models built following our serverless template. To understand how turboboot compatibility works, you can refer to turboboot documentation.
To learn how to deploy to Turboboot and see its performance improvements we made a short video.
What are users saying about Turboboot?
Last week we starting giving customers access to Turboboot. Over 10% of customers are already using Turboboot, here is what they are saying regarding performance with their custom models.